Plotting#
Spatialproteomics has a variety of plotting functions, enabling the plotting of intensities, segmentation masks, and predicted cell type labels.
If you want to follow along with this tutorial, you can download the data here.
[1]:
%reload_ext autoreload
%autoreload 2
import spatialproteomics
import matplotlib.pyplot as plt
import xarray as xr
[2]:
# loading in a data set
ds_unprocessed = xr.open_zarr("../../data/LN_24_1_unprocessed.zarr")
[3]:
# having a look at the dataset
ds_unprocessed
[3]:
<xarray.Dataset> Size: 576MB
Dimensions: (channels: 56, y: 3000, x: 3000, cells: 18134, features: 2)
Coordinates:
* cells (cells) int64 145kB 1 2 3 4 5 ... 18131 18132 18133 18134
* channels (channels) <U11 2kB 'DAPI' 'Helios' ... 'CD79a' 'Ki-67'
* features (features) <U10 80B 'centroid-0' 'centroid-1'
* x (x) int64 24kB 0 1 2 3 4 5 ... 2994 2995 2996 2997 2998 2999
* y (y) int64 24kB 0 1 2 3 4 5 ... 2994 2995 2996 2997 2998 2999
Data variables:
_image (channels, y, x) uint8 504MB dask.array<chunksize=(7, 375, 750), meta=np.ndarray>
_obs (cells, features) float64 290kB dask.array<chunksize=(9067, 2), meta=np.ndarray>
_segmentation (y, x) int64 72MB dask.array<chunksize=(375, 375), meta=np.ndarray>Plotting Channel Intensities#
The slicing capabilities of xarray make data visualization very easy. The general pattern is here to first select the channels, image regions and labels of interest, and then to use the plotting functions that are available via the .pl accessor. Images can be shown by using the pl.show() method.
[4]:
# selecting the DAPI channel and showing the result with pl.show()
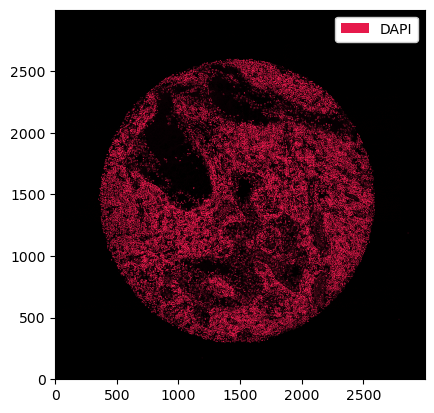
_ = ds_unprocessed.pp["DAPI"].pl.show()
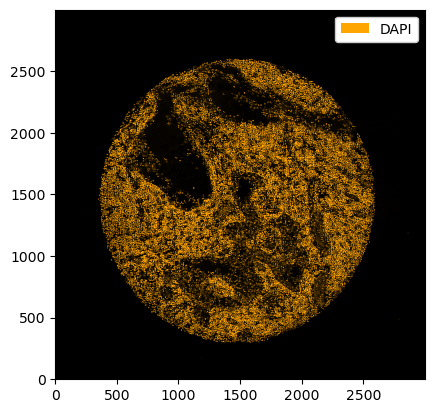
If we want different colors, we can specify those using the pl.colorize method.
[5]:
_ = ds_unprocessed.pp["DAPI"].pl.colorize(["orange"]).pl.show()
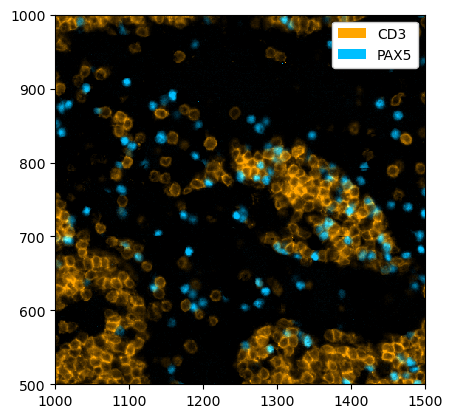
The pl.colorize function allows us to make image overlays quickly by first selecting the channels of interest. We illustrate this by first selecting the CD4 and CD8 channels and then assigning the colors.
[6]:
_ = ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000].pl.colorize(colors=["orange", "deepskyblue"]).pl.show()
All plotting functions accept matplotlib.Axes via the ax argument. This enables to easily modify plots using the normal matplotlib API. For example, let’s say we want to plot multiple channels in different subplots.
[7]:
# creating two subplots
fig, ax = plt.subplots(1, 2, figsize=(16, 8))
# populating the first subplot
# note how we set ax=ax[0] to tell the plotting function to use the first subplot
_ = ds_unprocessed.pp["DAPI", 1000:1500, 500:1000].pl.colorize(colors=["red"]).pl.show(ax=ax[0])
# populating the second subplot
_ = (
ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000]
.pl.colorize(colors=["orange", "deepskyblue"])
.pl.show(ax=ax[1])
)
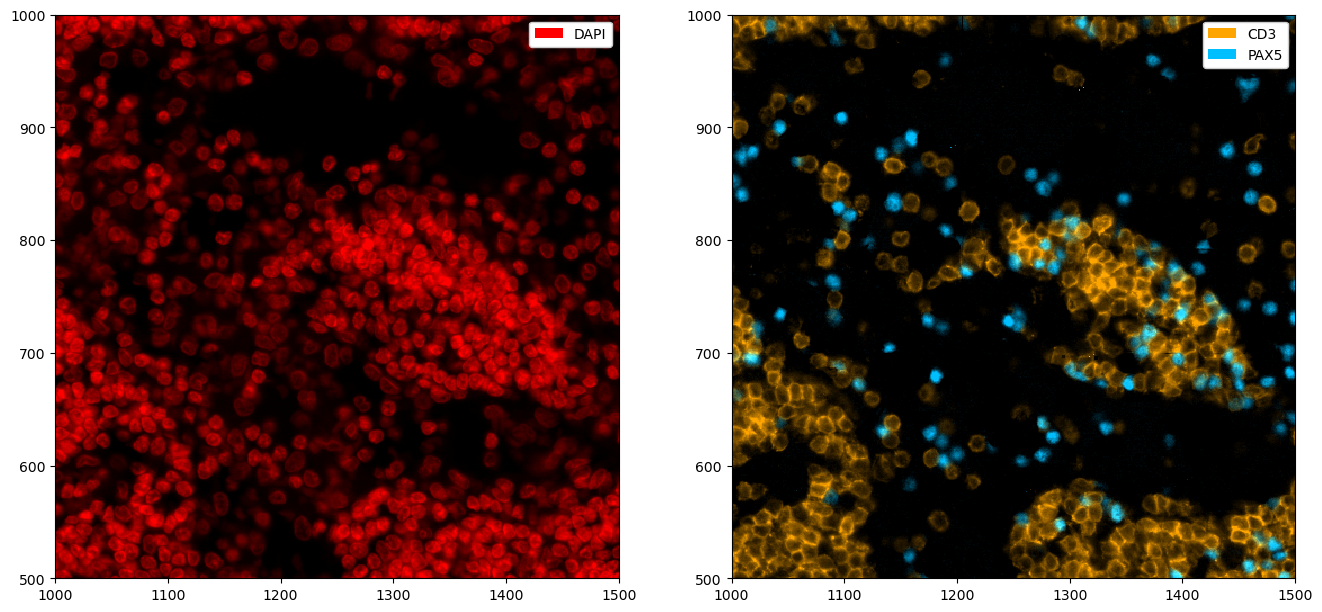
By default, a legend showing the colors corresponding to the channels is shown. You can disable this with the legend_image argument. In addition, matplotlib functions can be used to further alter the plot, e. g. to remove ticklabels. The code snipped below also highlights the pl.autocrop() function, which can be useful to remove empty space around a tissue microarray.
[8]:
fig = plt.figure(figsize=(8, 8))
_ = ds_unprocessed.pp["DAPI"].pl.autocrop().pl.colorize(colors=["red"]).pl.show(legend_image=False)
plt.xticks([])
plt.yticks([])
plt.tight_layout()
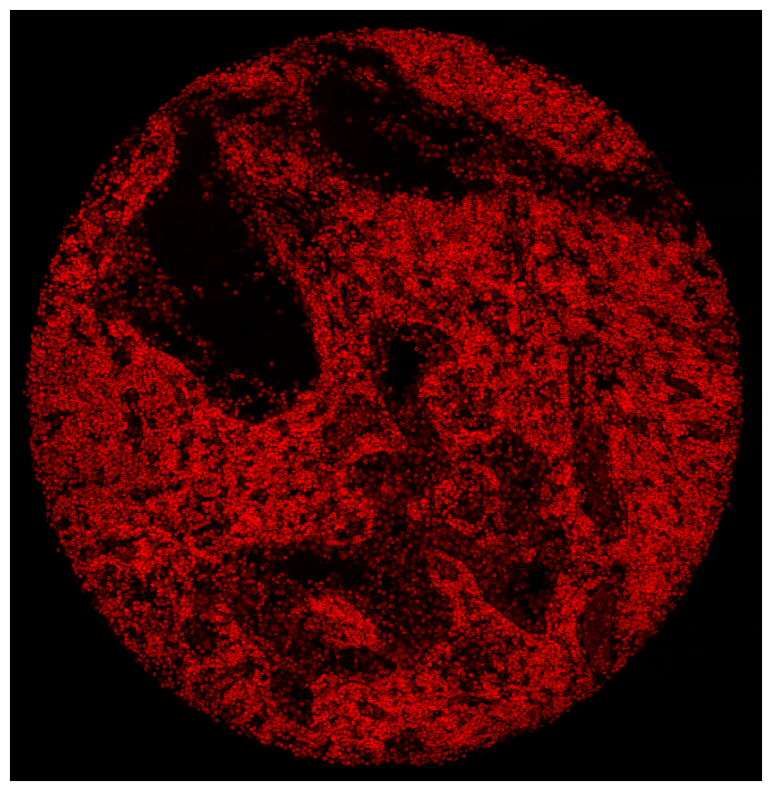
Rendering Segmentation Masks#
If your spatialproteomics object contains a segmentation mask, you can simple plot it by setting render_segmentation to true.
[9]:
fig = plt.figure(figsize=(8, 8))
_ = (
ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000]
.pl.colorize(colors=["orange", "deepskyblue"])
.pl.show(render_segmentation=True)
)
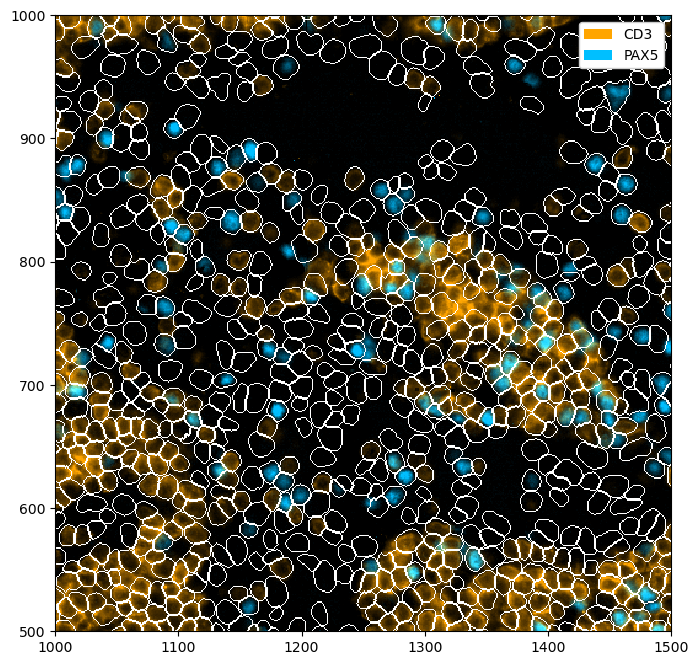
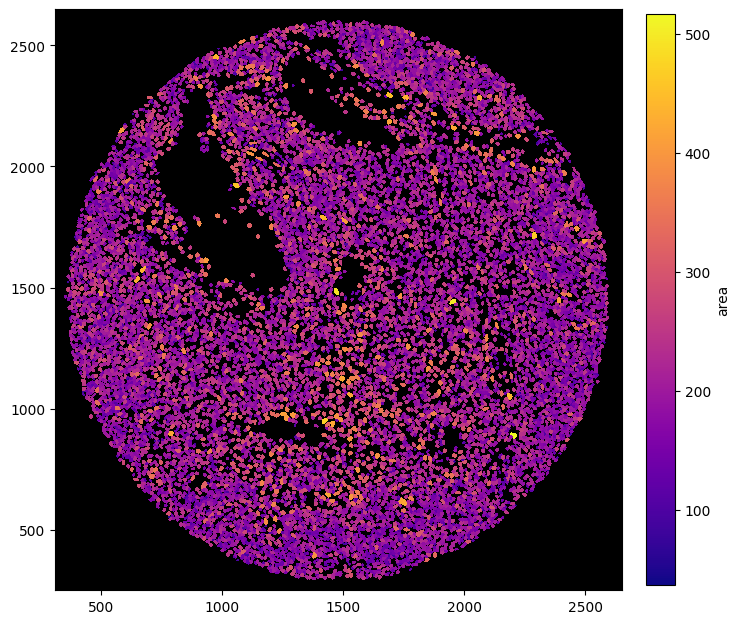
Rendering Obs#
Sometimes, you might want to visualize specific features, such as the cell size. With spatialproteomics, you can do this while retaining the cell shapes obtained by the segmentation.
[10]:
fig = plt.figure(figsize=(8, 8))
_ = (
ds_unprocessed.pp.add_observations("area")
.pl.autocrop()
.pl.render_obs(feature="area", cmap="plasma")
.pl.imshow(legend_obs=True)
)
[11]:
fig = plt.figure(figsize=(8, 8))
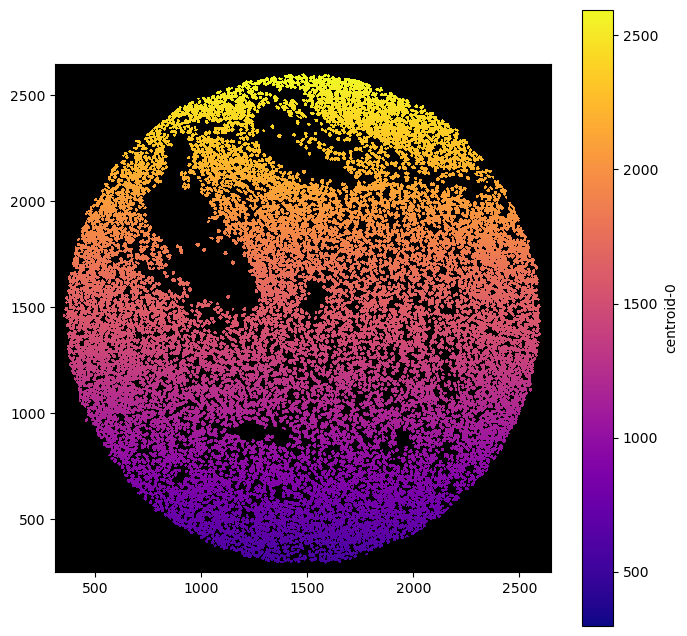
_ = ds_unprocessed.pl.autocrop().pl.render_obs(feature="centroid-0", cmap="plasma").pl.imshow(legend_obs=True)
Rendering Labels#
Similar to render_segmentation, pl.show() also has an argument called render_labels, which can be used to render cell type labels. We can simultaneously deactivate the rendering of the intensities to get an image of only the labels.
[12]:
# reading in a dataset containing labels
ds = xr.open_zarr("../../data/LN_24_1.zarr")
# setting colors for nicer visualizations
celltype_colors = {
"B cell": "#5799d1",
"T cell": "#ebc850",
"Myeloid cell": "#de6866",
"Dendritic cell": "#4cbcbd",
"Macrophage": "#bb7cb4",
"Stromal cell": "#62b346",
"Endothelial cell": "#bf997d",
}
ds = ds.la.set_label_level("labels_0", ignore_neighborhoods=True).la.set_label_colors(
celltype_colors.keys(), celltype_colors.values()
)
[13]:
fig = plt.figure(figsize=(8, 8))
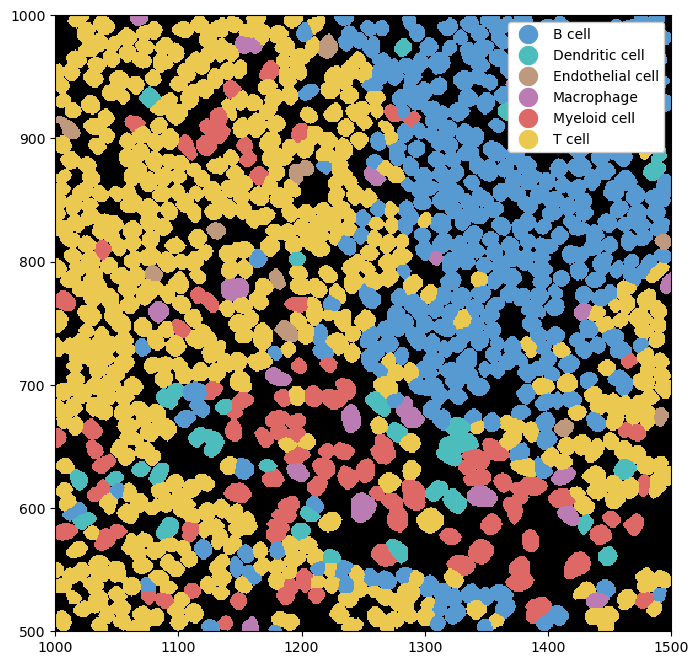
_ = ds.pp[1000:1500, 500:1000].pl.show(render_image=False, render_labels=True)
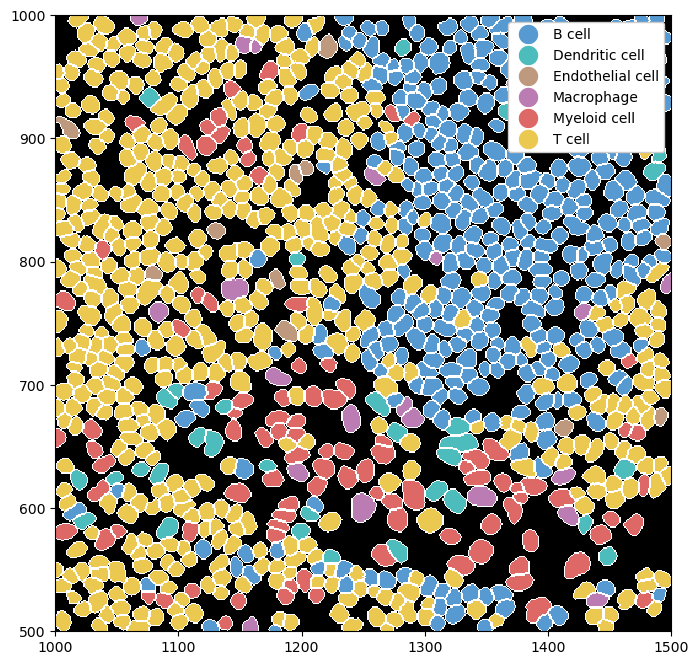
We can combine this with rendering the segmentation masks for a clearer picture of where exactly the cell boundaries lie.
[14]:
fig = plt.figure(figsize=(8, 8))
_ = ds.pp[1000:1500, 500:1000].pl.show(render_image=False, render_segmentation=True, render_labels=True)
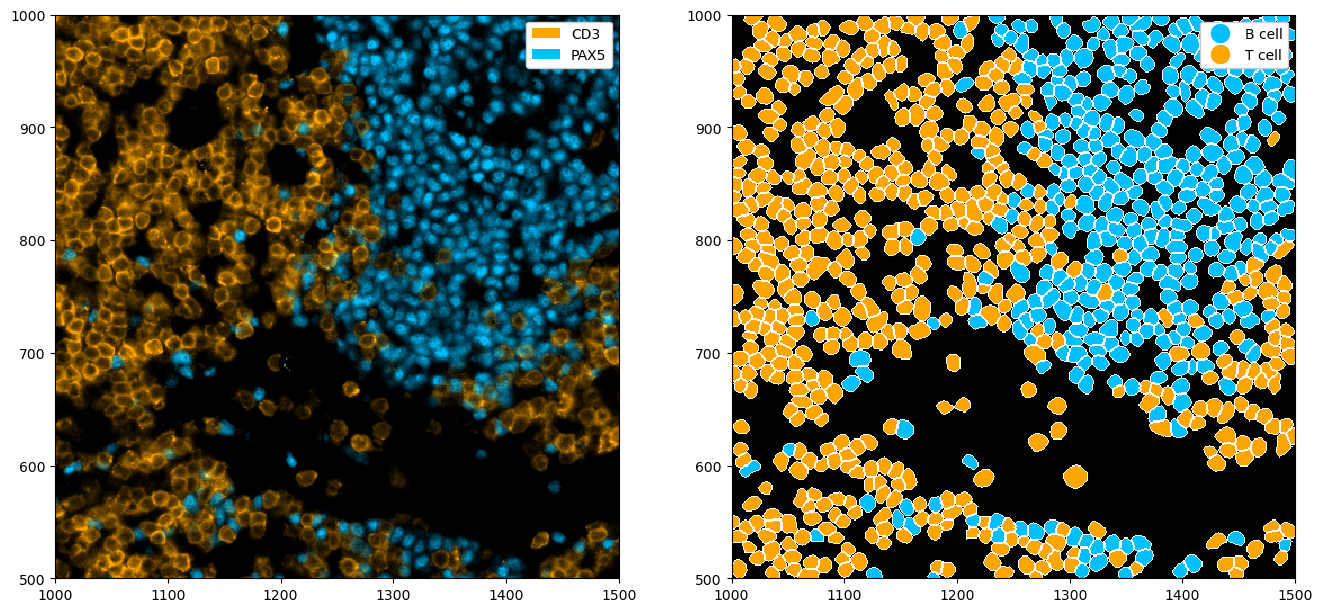
Using the .la[] accessor we can also subset cell labels, rather than displaying all of them. We can also use the la.set_label_colors() to set custom colors for our labels.
[15]:
fig, ax = plt.subplots(1, 2, figsize=(16, 8))
_ = ds.pp[["CD3", "PAX5"], 1000:1500, 500:1000].pl.colorize(["orange", "deepskyblue"]).pl.show(ax=ax[0])
_ = (
ds.pp[1000:1500, 500:1000]
.la["T cell", "B cell"]
.la.set_label_colors(["T cell", "B cell"], ["orange", "deepskyblue"])
.pl.show(render_image=False, render_segmentation=True, render_labels=True, ax=ax[1])
)
Rendering Neighborhoods#
We can also render neighborhoods. How to obtain such neighborhoods is shown in the Neighborhoods notebook.
[16]:
# obtaining an object that already contains neighborhoods
ds_neighborhood = xr.open_zarr("../../data/LN_24_1.zarr")
[17]:
# setting neighborhood colors
ds_neighborhood = ds_neighborhood.nh.set_neighborhood_colors(
[f"Neighborhood {x+1}" for x in range(6)], ["lightgray", "gray", "darkgray", "gold", "deepskyblue", "purple"]
)
# plotting the neighborhoods
fig = plt.figure(figsize=(8, 8))
_ = ds_neighborhood.pl.show(render_image=False, render_neighborhoods=True)

Annotation of Regions or Cells#
We can also annotate regions or cells within the plots.
[18]:
# highlighting a region with pl.add_box()
fig = plt.figure(figsize=(8, 8))
_ = (
ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000]
.pl.colorize(colors=["orange", "deepskyblue"])
.pl.add_box([1230, 1480], [640, 840])
.pl.show()
)
[19]:
# selecting all B cells and annotating them with pl.annotate()
fig = plt.figure(figsize=(8, 8))
_ = (
ds.pp[["CD3", "PAX5"], 1500:2000, 1200:1700]
.la["B cell"]
.pl.colorize(colors=["orange", "deepskyblue"])
.la.set_label_colors(["B cell"], ["deepskyblue"])
.pl.annotate()
.pl.show(render_labels=True, label_kwargs={"alpha": 0.0})
)
Expert Plotting#
To gain more control over your plots, you can use the functions colorize, render_segmentation, and render_labels in combination with imshow (instead of show, which provides a high-level wrapper around these). Those methods allow for more nuanced adjustments of the final plot. Here are a few examples, for more details please consult the documentation of the corresponding methods.
[20]:
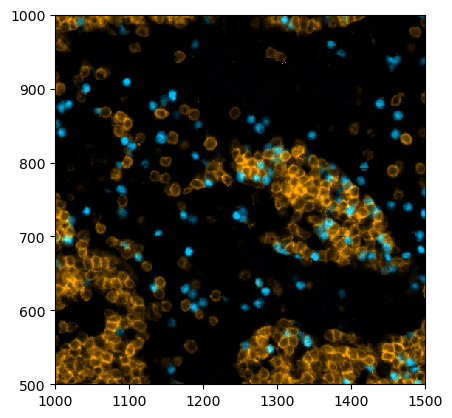
_ = ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000].pl.colorize(colors=["orange", "deepskyblue"]).pl.imshow()
[21]:
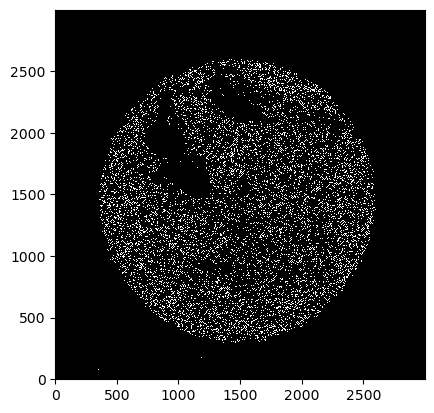
_ = ds_unprocessed.pl.render_segmentation().pl.imshow()
[22]:
_ = ds.pl.render_labels().pl.imshow()
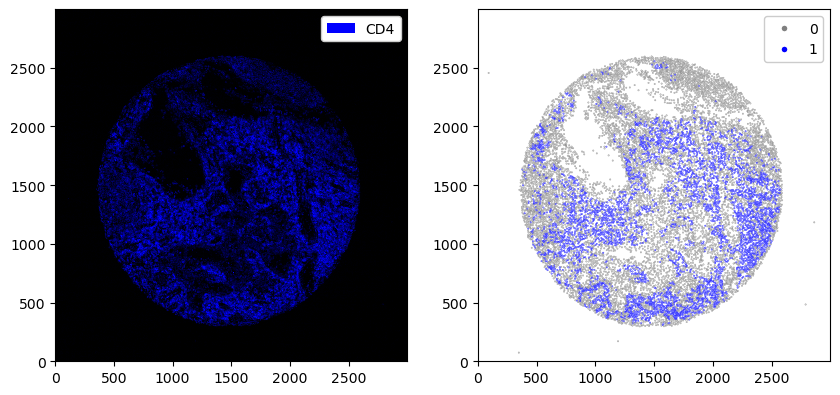
[23]:
_ = (
ds_unprocessed.pp[["CD3", "PAX5"], 1000:1500, 500:1000]
.pl.colorize(colors=["orange", "deepskyblue"])
.pl.render_segmentation()
.pl.imshow()
)
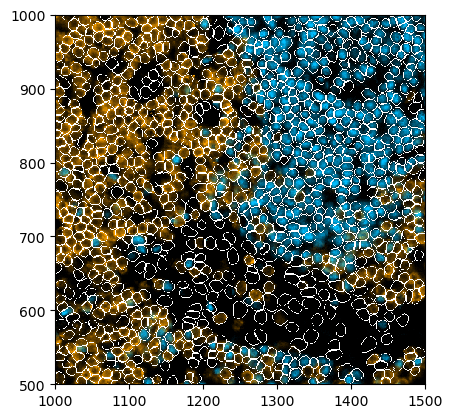
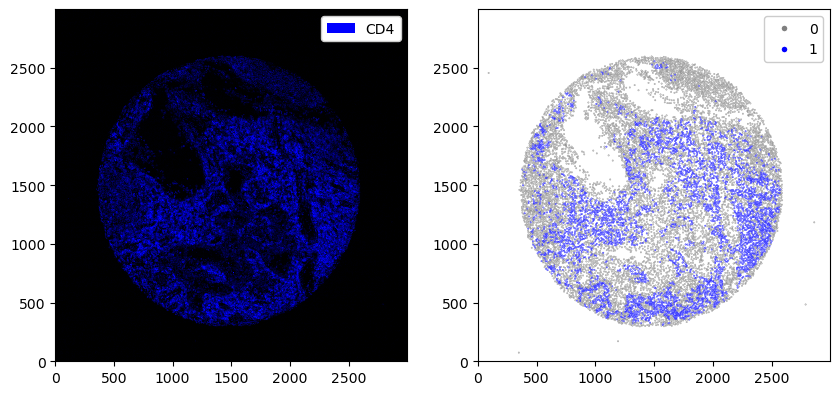
You can also use scatterplots instad of always plotting the images.
[24]:
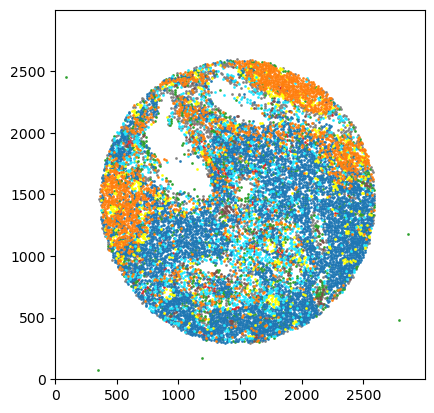
# creating a scatter plot of the labels
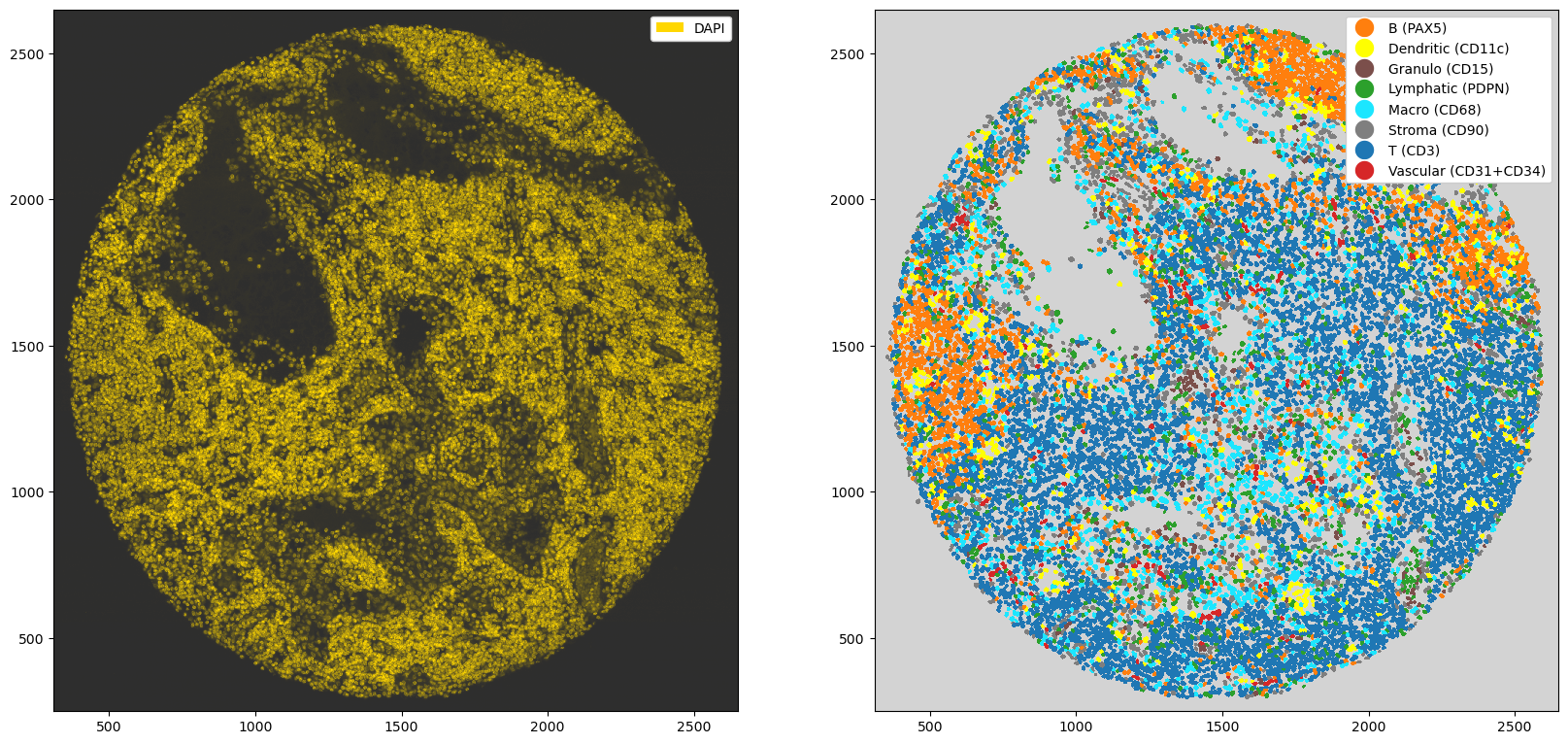
_ = ds.pl.scatter_labels(legend=False)
[25]:
fig, ax = plt.subplots(1, 2, figsize=(10, 20))
_ = ds.pp["CD8"].pl.colorize("blue").pl.show(ax=ax[0])
_ = ds.pl.scatter(feature="CD8_binarized", size=0.1, palette={0: "gray", 1: "blue"}, ax=ax[1])
[26]:
# creating a scatterplot of continuous variables
# adding area of each cell and plotting it
ds_tmp = ds.pp.add_observations("area")
_ = ds_tmp.pl.scatter(feature="area", scatter_kws={"cmap": "YlOrRd"})

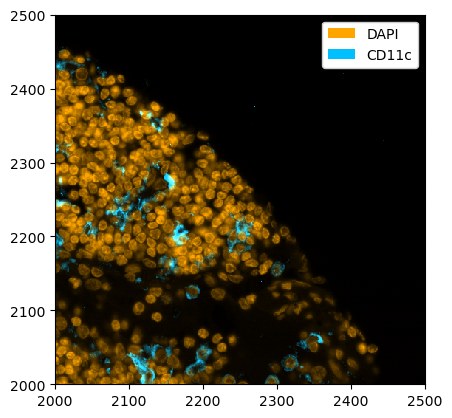
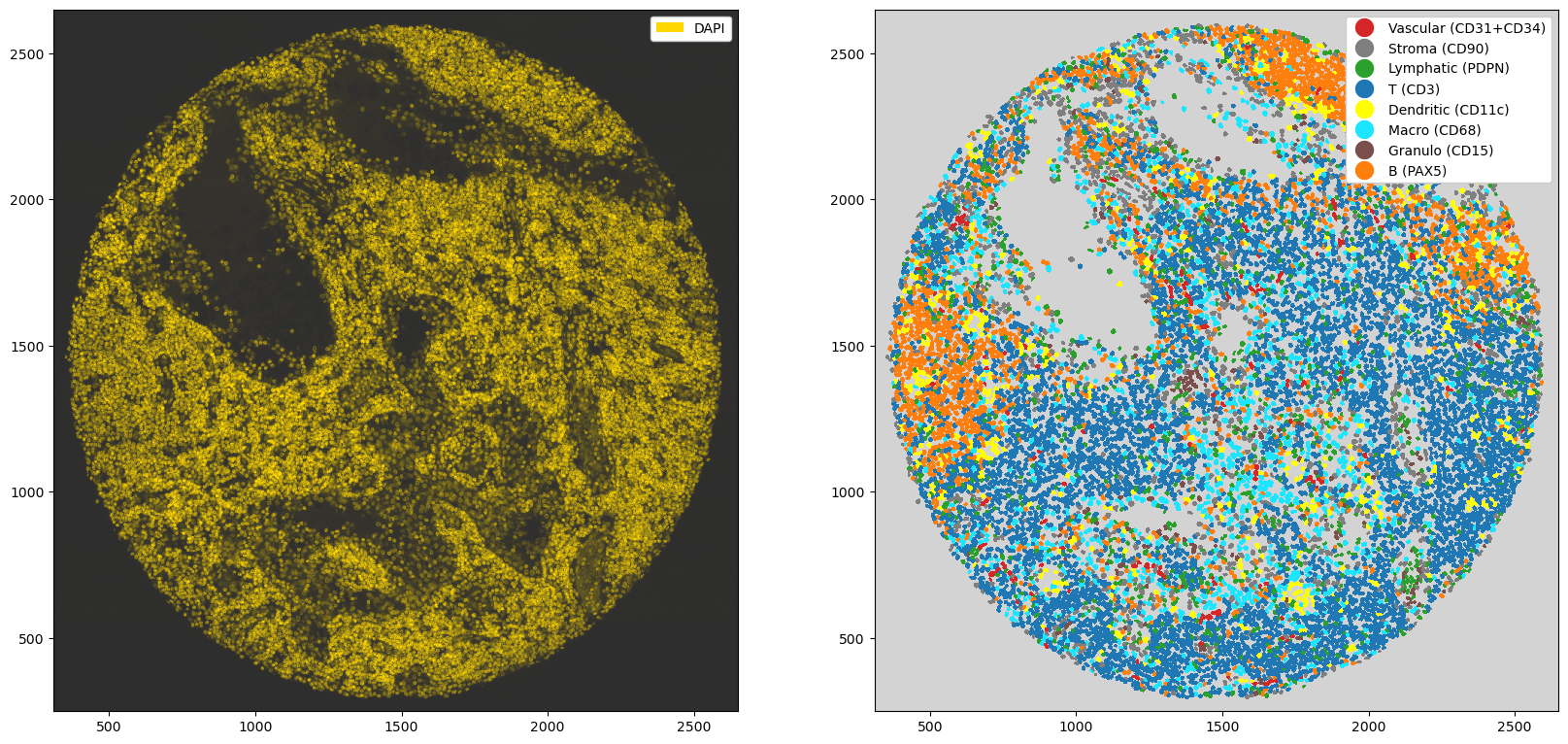
If you have multiple segmentation masks, you can show all of them at the same time like this.
[27]:
_ = ds_unprocessed.pp[["DAPI", "CD11c"]].pp[2000:2500, 2000:2500].pl.colorize(["orange", "deepskyblue"]).pl.show()
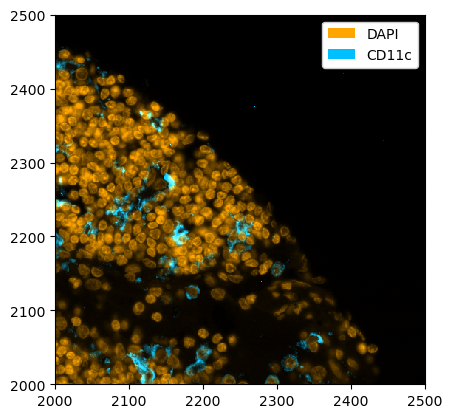
[28]:
ds_multisegmentation = (
ds_unprocessed.pp[["DAPI", "CD11c"]]
.pp[2000:2500, 2000:2500]
.tl.cellpose(key_added="_cellpose_segmentation", channel_settings=[0, 0])
)
Welcome to CellposeSAM, cellpose v
cellpose version: 4.0.4
platform: linux
python version: 3.10.0
torch version: 2.7.0+cu126! The neural network component of
CPSAM is much larger than in previous versions and CPU excution is slow.
We encourage users to use GPU/MPS if available.
Neither TORCH CUDA nor MPS version not installed/working.
>>>> using CPU
>>>> using CPU
>>>> loading model /home/meyerben/.cellpose/models/cpsam
Performing independent segmentation on all markers. If you want to perform joint segmentation, please set the channel_settings argument appropriately.
[29]:
plt.figure(figsize=(16, 16))
_ = ds_multisegmentation.pl.colorize(["gold", "deepskyblue"]).pl.show(
render_segmentation=True, segmentation_kwargs={"layer_key": "_cellpose_segmentation", "colors": ["white", "red"]}
)
We can also plot histograms of any table, for example the observations (e. g. cell area) or the marker distribution.
[30]:
# quick check what our object looks like
ds_tmp
[30]:
<xarray.Dataset> Size: 7GB
Dimensions: (labels: 7, la_props: 2, cells: 18134, cells_2: 18134,
channels: 56, features: 22, la_features: 4,
neighborhoods: 6, nh_props: 2, x: 3000, y: 3000)
Coordinates:
* labels (labels) int64 56B 1 2 3 4 5 6 7
* la_props (la_props) <U6 48B '_color' '_name'
* cells (cells) int64 145kB 1 2 3 4 5 ... 18131 18132 18133 18134
* cells_2 (cells_2) int64 145kB 1 2 3 4 ... 18131 18132 18133 18134
* channels (channels) <U11 2kB 'DAPI' 'Helios' ... 'CD79a' 'Ki-67'
* features (features) object 176B 'BCL-2_binarized' ... 'inter_la...
* la_features (la_features) object 32B 'labels_0' ... 'labels_3'
* neighborhoods (neighborhoods) int64 48B 1 2 3 4 5 6
* nh_props (nh_props) <U6 48B '_color' '_name'
* x (x) int64 24kB 0 1 2 3 4 5 ... 2995 2996 2997 2998 2999
* y (y) int64 24kB 0 1 2 3 4 5 ... 2995 2996 2997 2998 2999
Data variables:
_adjacency_matrix (cells, cells_2) int64 3GB dask.array<chunksize=(567, 567), meta=np.ndarray>
_image (channels, y, x) float64 4GB dask.array<chunksize=(4, 375, 375), meta=np.ndarray>
_image_raw (channels, y, x) uint8 504MB dask.array<chunksize=(7, 375, 750), meta=np.ndarray>
_intensity (cells, channels) float64 8MB dask.array<chunksize=(4534, 14), meta=np.ndarray>
_la_layers (cells, la_features) object 580kB dask.array<chunksize=(9067, 4), meta=np.ndarray>
_nh_properties (neighborhoods, nh_props) <U14 672B dask.array<chunksize=(6, 2), meta=np.ndarray>
_obs (cells, features) float64 3MB 0.0 0.0 ... 0.8421 0.1053
_segmentation (y, x) int64 72MB dask.array<chunksize=(375, 375), meta=np.ndarray>
_la_properties (labels, la_props) object 112B '#5799d1' ... 'T cell'[31]:
# plotting a histogram for a feature in the obs table
df = ds_tmp.pp.get_layer_as_df("_obs")
_ = plt.hist(df["area"], bins=50)
[32]:
# plotting a histogram for a feature in the expression matrix
df = ds_tmp.pp.get_layer_as_df("_intensity")
_ = plt.hist(df["DAPI"], bins=50)
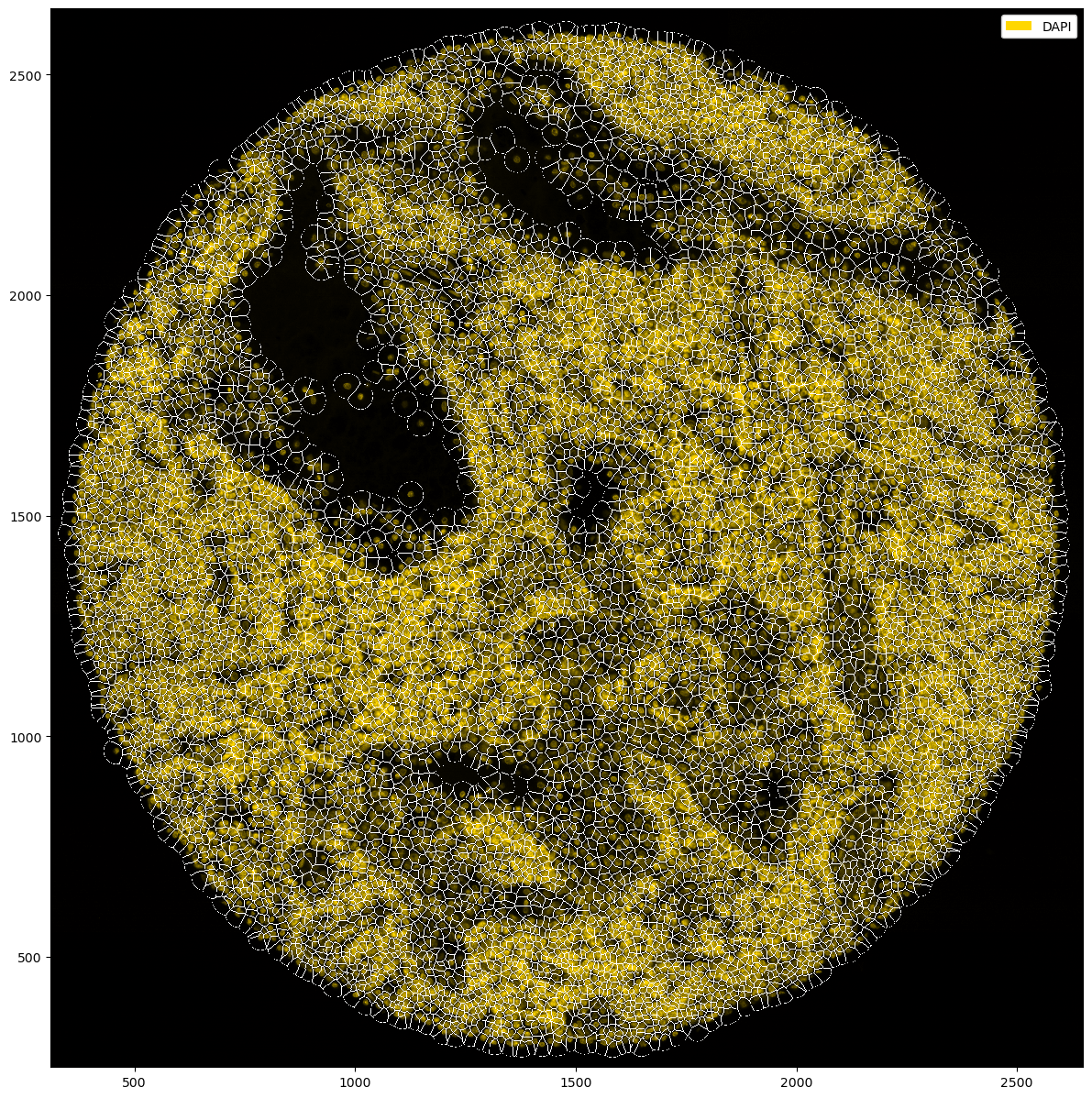
Sidenote: you can also create a Vornoi diagram of your data by simply growing segmentation masks by a specified distance.
[33]:
plt.figure(figsize=(15, 15))
_ = (
ds_tmp.pp["DAPI"]
.pp.grow_cells(iterations=20)
.pl.autocrop()
.pl.colorize("gold", layer_key="_image_raw")
.pl.show(render_segmentation=True)
)
Mask growing requires recalculation of the observations. All features other than the centroids will be removed and should be recalculated with pp.add_observations().
For visualization, it is also possible to adjust the background color of the image. However, caution is advised when plotting fluorescence intensities on light backgrounds, as the background colors get mixed with the actual fluorescence values.
[34]:
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
# you can pass the background either in the pl.colorize() method or in pl.show()
_ = ds_tmp.pp["DAPI"].pl.autocrop().pl.colorize("gold", background="#2e2e2e", layer_key="_image_raw").pl.show(ax=ax[0])
_ = ds_tmp.pp["DAPI"].pl.autocrop().pl.show(render_image=False, render_labels=True, background="lightgray", ax=ax[1])